


Agile: Dead End? Not if we go the next step and try new ways to become faster and better. Continuous learning and improvement, a core principle of Agility, means that we have to go out of our comfort zone from time to time. As paradox this might sound, it also means: Going beyond Agility and going beyond what we currently do with Agility: Scrum, SAFe, Agile Leadership, the mindset shift hype and so on. Although they are all so important for success, we should avoid Agile becoming a victim of it’s own frameworks, a bubble community on it’s own, fighting against „this is not agile“. And this also means that we can bring Lean and IT Service Management – often declared as dead, to new life, but by taking a different perspective to support our goals. Together with some new and exciting DevOps practices, which make agility and continuous improvement happen! I strongly believe the DevOps movement effectively helps us with that to achieve what we all want as companies: Impact, customer value and becoming a real player in the digital age. All the trends, methods and frameworks are just a means to an end with no value in itself. As a DevOps trainer from the very first days and and Agile, DevOps & Service Management consultant for many years, I had the privilege to learn, coach and experience many DevOps practices. In the following I would like to share some of them. First starting with the challenge we face, then going to the actual practices (covering people, process, technology) and ending with some tips on how to approach it (transformation).
State of Agile 2019 and the problem we are facing
In the recently published 13th State of Agile Report, 73% of the respondents stated that they currently have DevOps initiatives in their organization or are planning a DevOps initiative within the next 12 months. It also states „organizational culture“, „resistance to change“ and „inadequate management support“ as main challenges for agile success. Hmm…, every year the same challenges. All no surprise to me. Why? Although 97% of the 5000 respondents all over the globe claim they use agile development methods (some of them may even made a real cultural change including leadership) this is what I see in reality:
- How can we even talk about agile when we still have widely Water – Scrum – Fall situations: In front of the customer an IT demand management, passing over requirements the „agile team“, handing over to integration and various test phases?
- Silos – Cultural, functional, incentives: Developers wants change, Operations wants stability. What does the Business want? Functional teams with different goals and bosses with different incentives. Does anyone understand the end-to-end flow?
- Provisioning: How long does your 3 week Sprint take when you wait 4 weeks for the firewall change? How can we be agile if we still have monolithic systems and dependencies, which hinder agility?
- „Them and Us“ blaming cultures instead of common goals towards customer value
DevOps (just in a nutshell to make the link to the rest)
First of all: DevOps is a movement and not a framework, with the goal to become faster and better. Originally influenced by Unicorns such as Spotify, Netflix and Netsy, it brings together various ideas from Agile, Lean and IT Service Management. It comes to life through emerging practices that are delivering real value in real enterprises.
The DevOps Why? Pretty simple and convincing:
- Your next competitor could be Google or another unicorn. These unicorns are able to act extremely quick, make experiments and bring new robust products on the market
- Siloed organizations: Developers wants change, Ops wants stability. Silos, „no skin in the game“ and handovers everywhere – it can’t go on like this
The core principles of DevOps build around the 3 Ways:
- Understand and increase flow – from inception to value delivery
- Shorten and amplify feedback loops
- Continuous learning and experimentation
These principles are supported by various practices. The following image summarizes this up pretty well:
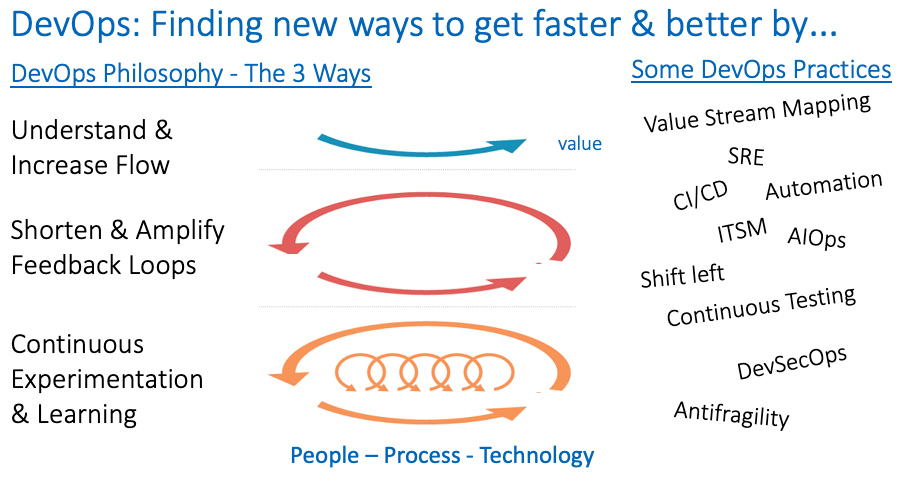
DevOps in a Nutshell
The term „DevOps“can be pretty misleading, it should actually be something like „BizDevSecQAOpsRun“, as it was always the intention to cover the end-to-end value stream. So consider it just as a label – it’s a typical American reduction 😉
Both scenarios – waterfall an agile – can benefit from DevOps. DevOps as an enabler for Agility (which the blog is referring to) enables earlier feedback (faster), releasable software within a cycle (better) and end-to end accountability within small team units.
So let’s focus now on some practices, which I want to share in the following and which I saw successfully used at various companies.
Value Streams and Value Stream Mapping: Starting where you are
Unless you are a startup and can therefore pursue a „greenfield“ approach, it is very wise to start where you are. So let’s get all involved on a table, visualize and optimize work along the flow and put customer value into the center! The first thing to realize is that we should organize and collaborate of „what creates value“. Products and Services create value! This can be for example an application, internal (used by the business) or external (an e-banking app). But also supporting product/services like infrastructure or a monitoring services which are effectively used by the first mentioned ones. Behind each product/service there is a current value stream, e.g. from inception to release (this is actually when value is created).
With the goal to improve, A Value Stream Mapping workshop follows typically these steps:
- Visualize and agree on a current Value Stream: How does work currently flow through the organization – across the silos? Not how it is documented and how we intend to work, but how we really work (Gemba!)
- Identify main bottlenecks: Where do we wait? Where is the waste? Where do we have unnecessary handovers? Where do we detect issues very late?
- Prioritize and agree which bottlenecks to address first
- Find improvement measures for it, having the end-to-end picture in mind: Things like automation, test improvements, shorter feedback loops.
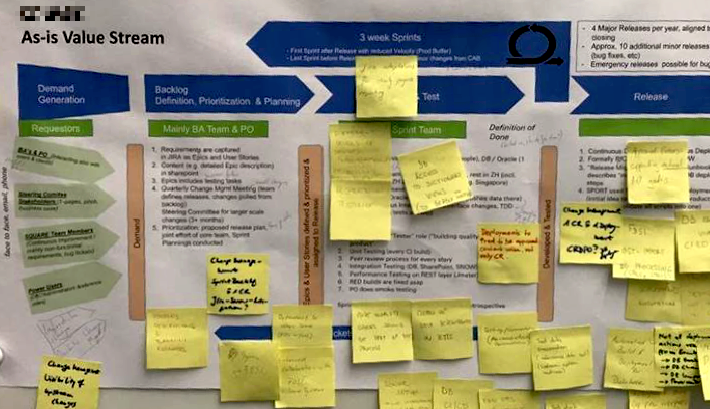
A real-live Value Stream Mapping example
I had the opportunity to lead such Value Stream Mapping Workshop several times. From my point of view VSM is a good starting point to identify where current issues with products and service value streams and make quick improvements that matters. And the team is usually commited to them, because it’s not a manager or consultant who tells them what to do, but it’s themselves.
So what about DevOps mindset and cultural shift?
Over the last 2 years there has been a strong emphasize on mindset / culture shift towards agility and lot’s of publications around that. Right, „culture eats strategy for breakfast“ (Peter Drucker) and yes, you can do perfectly do Scrum, but not be agile at all. But how do we change culture? It’s not through nice words (values, manifesto etc), but through actual behaviour. At a certain point new behaviour becomes culture – just „the way we do things“. This is why „doing“ new practices is so important and over time it just becomes culture. Written values & principles is culture made explicit and can support from the other side. Culture change is hard indeed and takes time, and I actually like this illustration to show what it means on employee as well on leadership level:
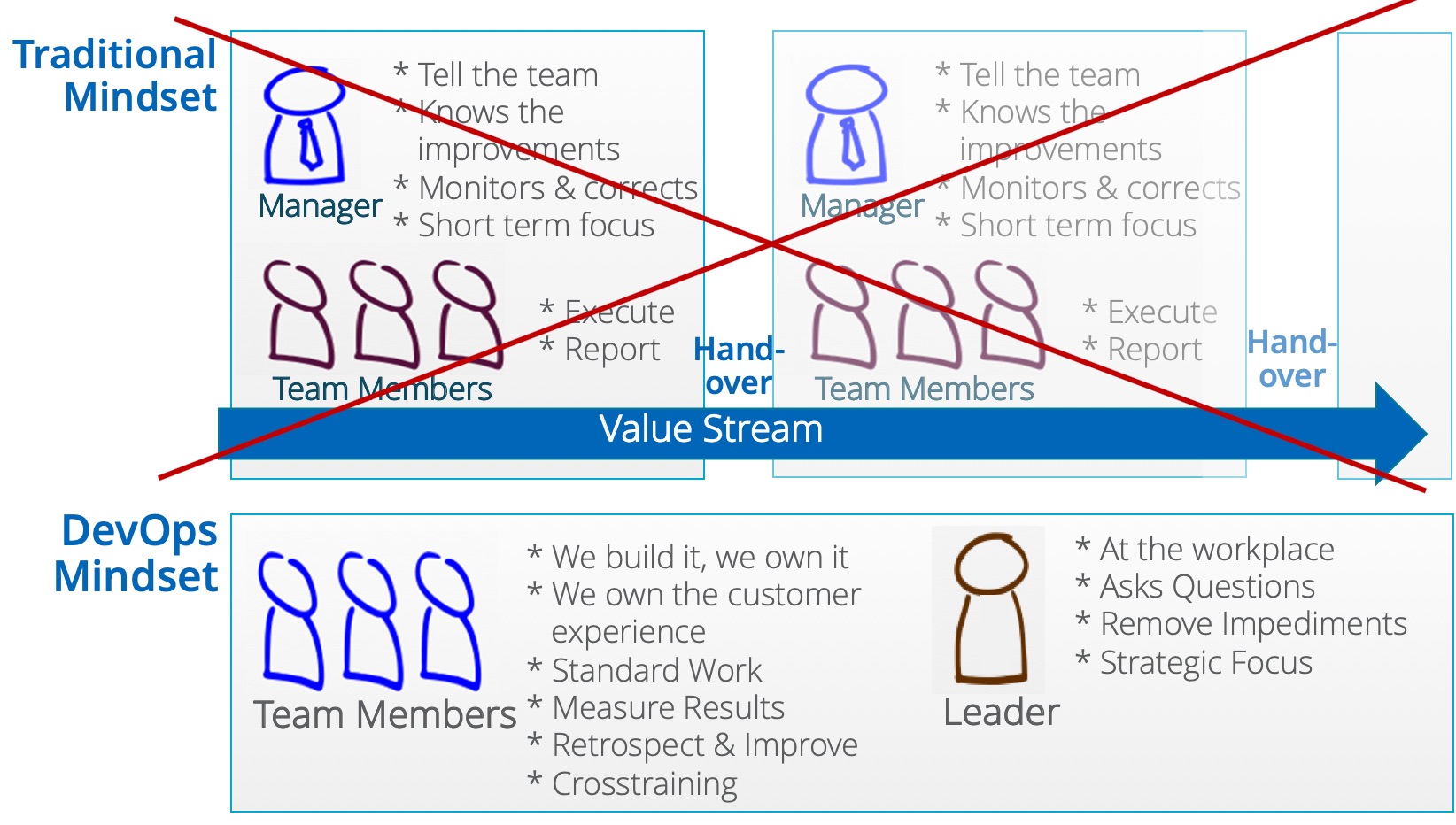
From traditional to DevOps mindset – people organize and collaborate around products and value streams
Having „Skin in the Game“ is key for the DevOps mindset – feeling accountable as a team for a product or service end-to-end. And btw – if I talk about team I don’t mean org chart boxes, but rather people who build around the same goal (product->customer success) and closely collaborate around that.
It’s a System of Systems – decoupled, autonomous and optimally aligned
People build around products/services and the value streams behind it. DevOps brings Agile to the next level by looking at the end-to-end value streams behind them. One of the big challenges I see in many companies is on how to design the whole system, that teams can act autonomously and at the same time aligned with each other. On top, it makes sense to differentiate between outside services and enabling services – such as monitoring, infrastructure as code & shared testing practices – as own value streams, decoupled from the rest. This also requires that instead of trying to manage complexity (through cumbersome processes and handovers), you rather reduce complexity by getting rid of dependencies, which usually needs a lot of work on architecture side (decoupling).
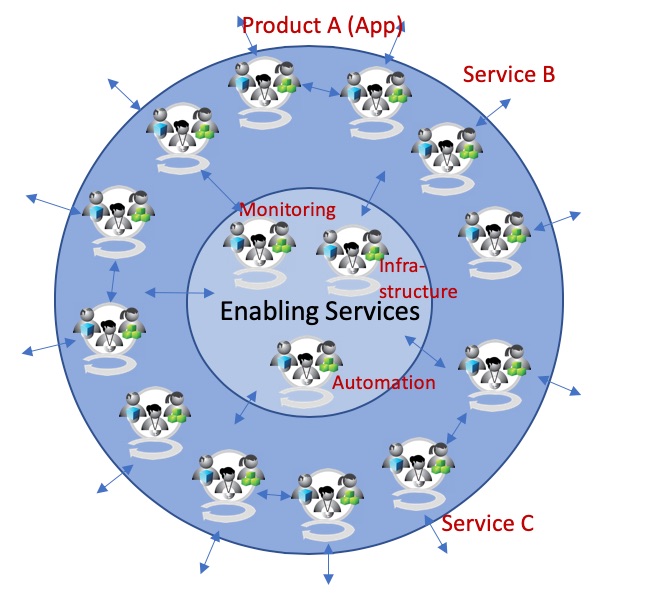
Outside In: Autonomous teams, aligned with each other. With some examples.
In one of my next blogs, I will go deeper into the question of Scaling, Organization Design, decoupled architectures and how to bring autonomy & alignment into the right balance.
Shift Left
New mindset & culture, real improvements – how can we actually change? Besides putting value streams in the center, building people around that and making them accountable: Shift left is one of the main practices. Shift left is about building quality very early into the product or service. By shifting left, fewer things break in production. An example out of the software world: Whenever code is checked in during development, security scripts automatically run, to ensure compliance with certain security guidelines. Shift left pursues instant feedback & correction instead of very late detection (which is typical for waterfall setups).
What does this concretely mean – coming out of an agile setup, but still with many silos around that? Question: As an Agile team, when do you consider something as done? When it’s tested, to what extend? What about things that have been always considered as „somebody else’s“ responsibility?
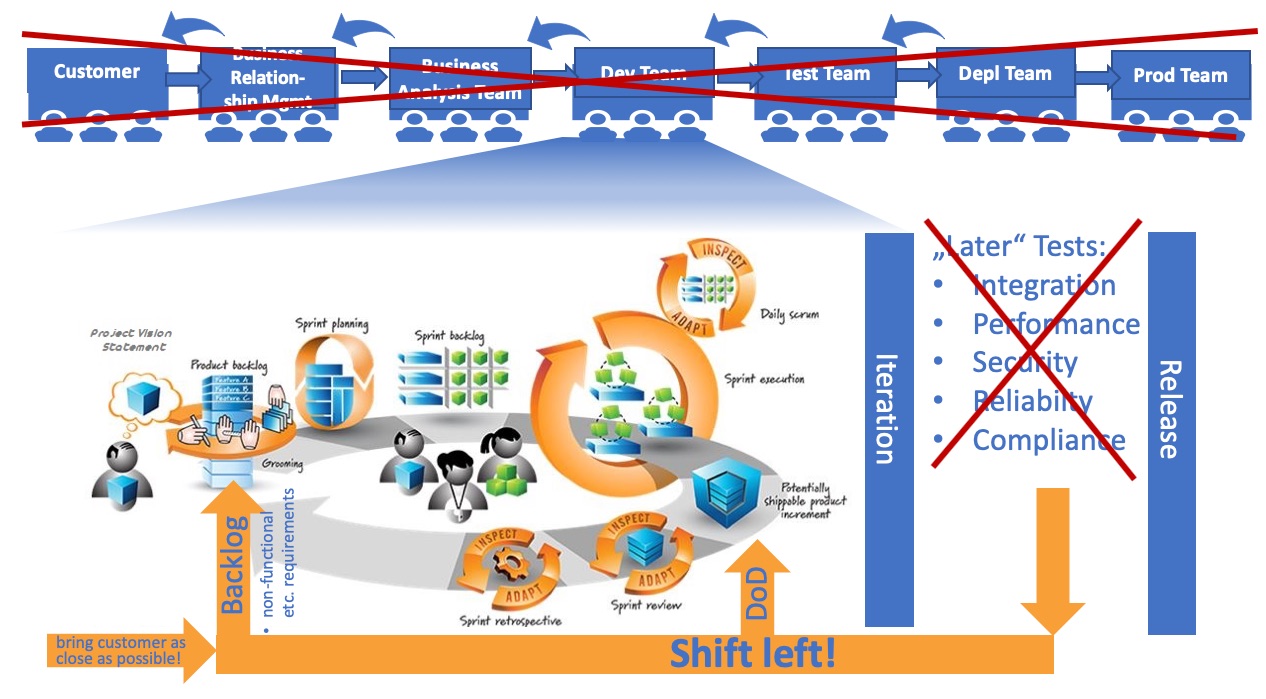
Shifting left in an Agile environment
So practically there are two things to consider from an agile perspective:
- Shift left by gradually improving the definition of done
- Make Ops part of the team AND reflect non-functional requirements part of the product owner and the product backlog
Continuous Integration / Delivery (CI /CD) & the DevOps Pipeline
Ok, I am now getting a little bit more technical, but besides people & process aspects , DevOps will not work without technology! Remember about Value Stream Mapping? And let’s go now beyond the „As is“ Value stream, which is usually full of manual steps and silos. If you could start from the scratch – what about that:
- Software is always in a releasable state. When I check in code into a shred respository, the various environments are automatically provisioned through the cloud and my features run down the DevOps pipeline. Automatically tested, from unit until functional- and non-functional tests.
Of course this is rather a vision than something you can achieve tomorrow. But it is something you can move towards in small steps.
If you are familiar with Lean Management and the Toyota Producation System (TPS) you will realize that old lean principles just have been applied to software development:
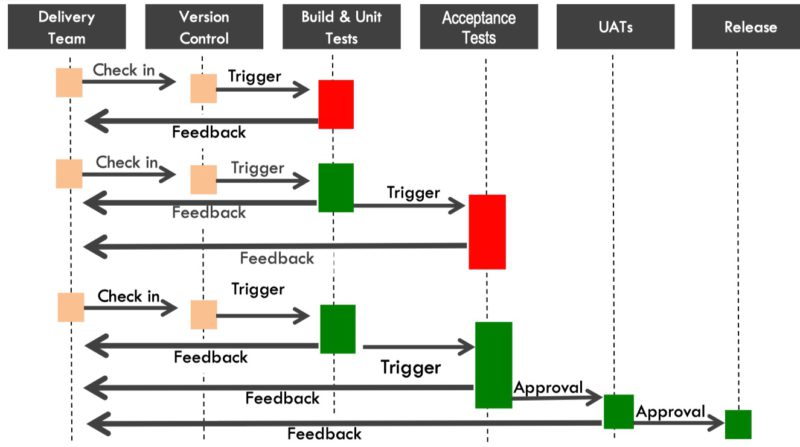
DevOps Pipieline: Negative feedback – stop the line! Source: Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation by Jez Humble
While Continuous Integration is quite a common practice, Continuous Delivery brings the Value Stream to a new level and a completely new way of working, because software is always in a releasable state. The DevOps pipeline acts as a vehicle and enables agility:
- Fast delivery of requirements, tested and enabling real feedback from the customer
- Enabling fast experiments on the markets: Does the customer really wants this? Are we right with our hypothesis? The Google way of success
There are a lot of implications out of that and effective CI/CD will not work without Infrastructure as Code (IaC), a new way of testing and automation, which I want to to touch next.
Infrastructure as Code (IaC) and decoupled architecture
With IaC, infrastructure is programmatically provisioned through the DevOps pipeline. Literally a line of code. For example a test environment with a certain configuration, within seconds. The cloud, internal or public, plays a significant role in that, for example an Amazon AWS with a Redhat Openshift instance on top. Interesting from a business perspective: These platform come with a high robustness in itself, something Ops was dealing with in the past in a cumbersome way. One conclusion for me: In „DevOps“, the role of „Ops“ is not to bring stuff into production, but to make it easy for the products teams that they can do it by themselves. By provisioning powerful and reliable infrastructure inclding the platforms on it. And it brings also a new reasoning for the cloud; In the past, many of the large enterprise cloud initiatives were done to save cost – provisioning of cheap and scalable storage on demand. A second reason was the replacement of commodity services such as eMail and CRM (Software as a Services). In the context of DevOps, the business case of the cloud is being an enabler for effective CI / CD.
A new emerging practice in this context is Site Reliability Engineering (SRE). Very much influenced by Google, the goal of SRE is to to create an ultra-scalable and highly reliable infrastructure and operations, on which the products and services build on. From an architect view it includes redundant and partitioned environments, decomposed into small services with decoupled deployments and monitoring/debugging hooks at all levels. This is what’s happening when a software engineer is tasked with what is used to be called operations ;-). I had the opportunity to attend the DevOpsDays Zurich last week, where Mary Poppendieck gave some great insights on the current state of SRE.
Automation Practices
The earlier mentioned DevOps pipeline, which steers the value stream through the various stages, is initiating various tests, monitoring, but also deployment. This only works if you improve and automate these rather specialized steps. For example, each check-in might include a performance test. Of course you don’t want to do this manually, but automate it. For example by using a Loadrunner script, which is called by the DevOps pipeline. DevOps has brought up a whole universe of tools – the whole trick is the make a toolchain out of it, with no breaks. One manual break -> no real CI/CD. Here just an example how this could work with Jenkins and a small selection of tools:
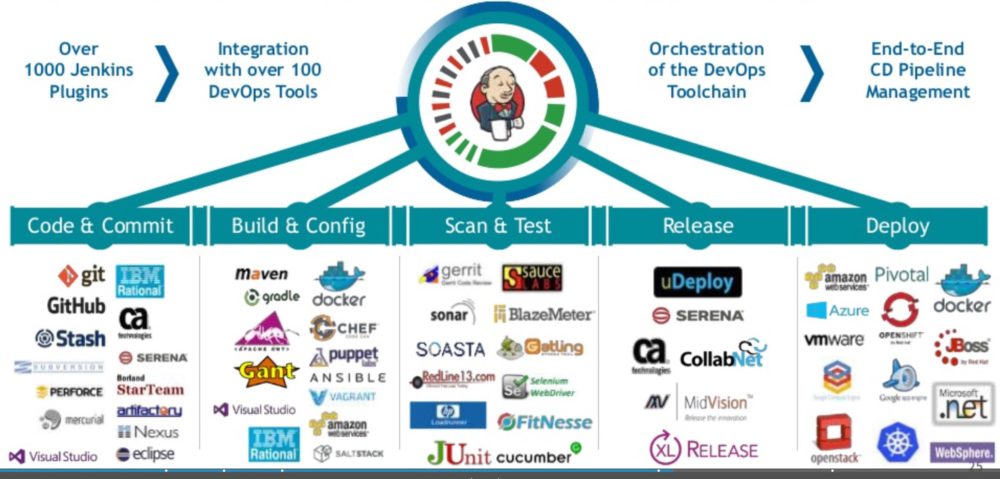
Example toolchain with DevOps Pipeline (automated stages) and specialized automations on each stage (lower part of image). Source. cPrime & Cloudbees
How can we effectively move forward in our automation efforts? My experience and my tip: Automation is something that you have to approach gradually by asking the following questions:
- Looking at the current value stream – where do we have manual steps, where do we have breaks?
- Business case: Where does it hurts the most? Where do we have the most benefits? What would be the cost/efforst behind an individual automation?
- Out of the prioritized list, you start with the top one, reassess and move forward
Again, we can close the loop and make the link the value stream – end to end and the customer value in the center!
New Ways of Testing
CI/CD enables you to get feedback fast and early. In DevOps, testing is happening continuously by executing automated tests as part of the deployment pipeline to obtain immediate feedback on the business risks associated with a software release candidate. I partially covered this already with Shift Left and the practices just mentioned.
On a mindset and organizational level, it also means, that testing is not the responsibility of somebody else. It’s the responsibility of the product team – skin in the game! – and they work on together to improve on that. Some additional practices might help you here from my experience:
- Test Driven Development (TDD): Requirements are defined in form of a test case, automated and integrated into the DevOps pipeline – before you start to build! This is especially important for regression tests.
- Having production-like environments.
- The product team is accountable, but I have seen success stories where common testing practices (e.g. performance) is offered as a shared service to to the product teams. Bring autonomy and alignment into the right balance!
How to approach it? See last chapter! (automation)
DevSecOps
DevSecOps as a practice has gained it’s own momentum and embraces Security as Code, shift left security testing Strategy and testing automation. Practices already explained in general in this blog, but now specifically applied to the security domain. The purpose and intent of DevSecOps is to build on the mindset that „everyone is responsible for security“ with the goal of safely distributing security decisions at speed and scale to those who hold the highest level of context without sacrificing the safety required domain. There are many practices around that, which I don’t want to go deeper (This blog is already way to long), but I found https://www.devsecops.org/ a great source of ideas.
Antifragility & Chaos Engineering
One of the biggest concerns of Unicorns like Netflix is that the whole system goes down because of a major incident. This is also a major concern for traditional companies, especially for applications directly used by their client. The challenge with many major incidents is, that they do not occur because of constellations you were thinking of, but rather because of the ones you didn’t. They are hard to predict. In here comes the concept of antifragility and I love the picture of the weed in the garden, which becomes stronger if you cut it. Or the Borg from Star Trek („resistance is futile!), which become stronger if they are attacked, because they learn from the enemy. These are examples of antifragily systems. They are different from robust systems, which are built for a certain purpose and also resist certain attacks (think of a medieval castle), because they learn from unpredictable situations.
Sounds like science fiction? Netflix is actually a good example of a real-live implementation. By randomly shutting down live containers, injecting other failures and closely monitoring the system, they can anticipate major incidents and take measures to prevent them. Another example I personally used was engaging trusted hackers and let them try to get into your system – a way to learn from that and preventing happing it in reality.
Rediscovering IT Service Management practices – by taking a new perspective and a new approach
IT Service Management, mainly represented by the framework ITIL, has been bashed a lot in the las years. And yes – there has been a lot of damage done – not because of the framework itself, but because of the implementations. ITIL processes have been implemented 1:1, leading to bureacracy, instead of adopting and adapting it in a lean way to the company’s goals. Organizations have been siloed and the value stream broken by making departments named by the titles of the ITIL books: Service Strategy, Service Design, Service Transition and Operation. Exactly what we don’t want today.
IT Service Management has brought up a lot of proven practices (I don’t call them processes by purpose), which smoothly integrate into DevOps and Agile and from which agile Product Team can learn a lot:
- Problem Management Practice: Preventing Incidents by identifying common root causes (=Problem), addressing and actually preventing them
- Event Management Practice: Very useful for continuous monitoring within the DevOps pipeline
- Thinking in Services, not Products: A Service is more than a product and Agile Product Owner can learn a lot from IT Service Management to incoporate especially non.functional requirements into their backlog
- And others like Incident Management, Service Catalogue Management and Request Fulfilment
Other practices: ChatOps and AIOps
Interesting as well. But for the sake to make this blog not too long I will stop with the practices here!
So what to do with all that? The Transformation Part
Now closing the loop, taking advantage of DevOps practices can be a next step in Agile, by looking at the value streams end-to-end, enabling fast and early feedback and overcoming silos in a company.
So where to start with that? DevOps is a journey and often embedded in an existing Agile Transformation and it’s goals. From that perspective there is not such a thing as a DevOps transformation, isn’t it? At the end, it’s all business transformation.
As in all transformations, it is always good to start where you are and moving towards a clear vision. One the one hand it is an excellent starting point to look at the value streams as outlined earlier. On the other hand a clear strategy outline is needed with the direction you want to go.
DevOps is a journey, which is different for every company, so make the journey itself Agile as well. Working with hypothesys (What do we believe is the right next thing for our organization) and validating this as early as possible to take the right next decisions. Nothing worse if you go a fixed transformation path and find out very late that this was the wrong direction.
All practices mentioned in this blog will help you to fill the transformation with life.
A model I use very often for transformation is the following one – Starting with a Vison and followed by a never ending circle of Assessment, Strategy, Pilot/Rollout and Reassessment:
![]()
Although DevOps is a continuous journey, I believe that you have to get some parts right at the beginning, which sometimes require „hard“ decisions:
- Skin in the Game: The Base for DevOps are the value streams and people buliding and collaborating around that. Make them accountable for it. The mindset „not my responsibility“ will just lead to no skin in the game and nothing will happen
- Measurement: Build up measurements such as Time to Market, Employee & Customer Satisfaction and stability to know if you are improving and measure it from the beginning
That’s (almost) it! Hope this helped – looking forward for feedback and intersting discussions!
Stay tuned!

